註:本文同步更新在Notion!(數學公式會比較好閱讀)
在深度學習的領域中,長短期記憶網路 (LSTM) 因為能夠解決長期依賴問題而廣為使用,但其複雜的結構在某些應用中導致了計算成本過高。為了簡化模型結構並提高計算效率,門控循環單元 (GRU, Gated Recurrent Unit) 應運而生。GRU 是 LSTM 的簡化版本,去除了部分門控機制,但仍然能有效解決序列學習中的長期依賴問題。
GRU 將 LSTM 中的三個門(輸入門、遺忘門和輸出門)合併成兩個門控機制,分別是更新門 (update gate) 和重置門 (reset gate)。這使得 GRU 模型更簡潔且具有更少的參數,但仍能有效控制信息的流動。
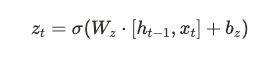
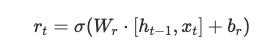
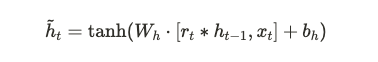
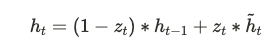

GRU 的主要特點是去掉了 LSTM 中的記憶單元,並且合併了部分門控機制。具體差異如下:
GRU 的數學推導基於反向傳播通過時間 (Backpropagation Through Time, BPTT),和 LSTM 一樣,主要目的是通過更新權重來最小化誤差函數。在這裡,我們關注的是梯度的傳播過程。由於 GRU 的結構更為簡單,其梯度計算相對 LSTM 更為直接,並且在實踐中,GRU 能夠更有效地避免梯度消失問題。
GRU 通常用於那些要求模型具有較高效能並能在保持準確率的同時降低計算複雜度的任務中。它特別適合於:
GRU 相對於 LSTM 的優勢來自於其簡化的數學結構,具體表現在以下幾個方面:
GRU 是 LSTM 的簡化版本,它以更少的參數和更簡潔的結構,實現了在大多數序列學習任務中與 LSTM 相近的性能。對於那些不需要處理極長期依賴問題的任務,GRU 通常是更具效率的選擇。在語音識別、自然語言處理和時間序列預測等領域,GRU 的應用越來越廣泛。
好想繼續放假在家躺平啊~~~

